 开云Kaiyun·体育官方网站 登录入口导致细巧力漂移并得出造作论断-开云(中国)Kaiyun·体育官方网站 登录入口
开云Kaiyun·体育官方网站 登录入口导致细巧力漂移并得出造作论断-开云(中国)Kaiyun·体育官方网站 登录入口
开云Kaiyun·体育官方网站 登录入口导致细巧力漂移并得出造作论断-开云(中国)Kaiyun·体育官方网站 登录入口
快科技5月1日讯息,DeepSeek在GitHub上发布了多模态推理模子及本事陈述,题为《Thinking with Visual Primitives(以视觉原语想考)》。
该模子基于DeepSeek V4-Flash(284B总参数、推理时激活13B的MoE架构)构建,建议了一种全新的多模态推理范式。

论文指出现存多模态大模子存在一个被冷漠的根人性瓶颈:“指代领域”(Reference Gap),即模子概况“看见”图片试验,但在推理经由顶用当然说念话构建想维链时,左边阿谁大的、聚辘集央的红色物体这类模糊描绘在密集场景中无法精详情位视觉对象,导致细巧力漂移并得出造作论断。
此前学界的主流应付场所是晋升感知分辨率,但论文以为看见和能说昭彰在说哪个是两件不同的事。
该模子的中枢革新在于将点坐标和领域框镶嵌推理经由自己,使其成为想维链的基本单位。模子在推理时每提到一个视觉对象就同步输出其坐标。
举例“找到一只熊[452,23,804,411],正在爬树,铲除,再往左下看,找到另一只[50,447,647,771],站在岩石边际,合适条件。”坐标不再是过后标注的谜底,而是推理经由中排斥歧义的空间锚点。

架构层面,模子终昭彰7056倍的视觉压缩,一张756×756的图片经ViT处分青年景2916个图像块token,经3×3空间压缩吞并为324个token,再通过压缩寥落细巧力(CSA)机制将KV缓存进一步压缩4倍,最终仅剩81个视觉KV条件。
算作参照,同等尺寸图片Claude Sonnet 4.6约需870个、Gemini-3-Flash约需1100个。
锻真金不怕火数据方面,团队从近10万个目标检测数据结伴筛选出约3.17万个高质料数据源,生成跨越4000万条锻真金不怕火样本,遮掩计数、空间推理、迷宫导航和旅途跟踪四类任务。
后锻真金不怕火领受先内行化、后调和战术,分裂锻真金不怕火领域框和点坐标两个内行模子,经强化学习优化后通过在线战术蒸馏吞并为调和模子。
实验效果在11个基准测试上与Gemini-3-Flash、GPT-5.4、Claude Sonnet 4.6等主流模子进行了对比。
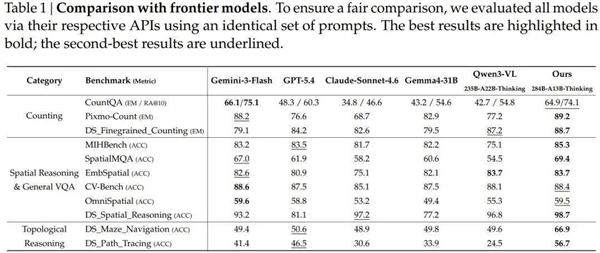
计数任务上,Pixmo-Count精准匹配得分89.2%,跨越Gemini-3-Flash的88.2%,大幅发轫GPT-5.4的76.6%和Claude Sonnet 4.6的68.7%。
最具代表性的差距出当今拓扑推理上:迷宫导航得分66.9%,GPT-5.4为50.6%、Gemini-3-Flash为49.4%、Claude Sonnet 4.6为48.9%,晋升约17个百分点;旅途跟踪得分56.7%,GPT-5.4为46.5%。
不外论文同期指出了面前局限性:模子需要明确触发词才会启用视觉原语机制,极细粒度场景下坐标精度有限,跨场景泛化才气仍有晋腾飞间。
